docker-swarm集群
集群
从主机层面来看 docker Swarm管理的是 docker_host集群 这个是一个重要概念 集群化(Clustring)
集群是由一组互相连接的服务器组成,各个服务协同工作
集群和多服务的区别:
集群能像单个系统那样工作,同时提供负载均衡-高可用等功能
使用集群部署应用时,只考虑需要多少内存和CPU,而不是考虑会使用哪台的CPU和内存。我们不应该关心应用会被部署在哪里,我们关心的是运行这个应用需要哪些资源,然后将它部署到集群,集群管理程序(比如Docker Swarm)会帮你搞定这些细节。
docker swarm mode
从 v1.12 开始,Docker Swarm 的功能已经完全与 Docker Engine 集成,要管理集群,只需要启动Swarm Mode。安装好 Docker ,Swarm和服务发现就已经存在,服务发现也在那里了,而且不需要安装Consul等外部数据库。
相比Kubernetes ,用Docker Swarm创建集群非常简单,不需要额外安装任何软件,也不需要做任何额外的配置
Swarm集群
- swarm是运行在docker Engine的多个主机组成的集群
- 当docker Engine初始化一个swarm 或者加入到一个存在的swarm时,就会启动swarm mode
- 没启动swarm mode时 docker执行的是容器的命令
- 运行swarm mode 后 docker增加了编排service的能力
- docker允许 在同一个docker_host上运行 swarm service的同时单独运行容器
swarm节点
swarm中的每个 docker engine都是一个node(每个dockerhost主机都是一个node节点)
分为 manager 和 worker
docker_node 执行部署命令 manager就会将部署任务拆解并分配给一个或多个 worker 完成部署
manager node负责执行编排和管理集群 保持并维护swarm处于期望的状态 (期望值是表示在swarm集群中永远容器的数量保持这个值不变)
worker node 接受并执行由manager node 派发的任务。默认配置下manager node 同时也是一个 worker node,不过可以将其配置成manager-only mode,让其专职负责编排和集群管理工作。
worker node 会定期向manager node 报告自己的状态和他正在执行的任务状态,这样,manager 就可以维护整个集群的状态
swarm 状态
- 分为 leader 和 reachable 状态
- 当leader宕机后,会有一个 reachable 被选为 leader继续进行管理集群的工作
docker service
- service定义了 worker node上要执行的任务,swarm的主要编排任务就是要保证service处于期望状态下(最少运行多少容器)
如:在swarm 中启动一个http访问,使用的镜像是httpd:lastes,副本数是3
manager node 负责创建这个service ,经过分析指导需要启动3个httpd 容器,根据当前各worker node 的状态将运行容器的任务分配下去,比如worker1 上运行两个容器,worker2上运行一个容器。
运行了一段时间,worker2 突然宕机了,manager 监控到这个故障,于是立即在worker3 上启动了一个新的httpd容器。
这样就保证了 service 处于期望的三个副本状态。
swarm 任务状态
| 状态 | 解释 |
|---|---|
| NEW | 任务初始化 |
| PENDING | 已分配任务资源 |
| ASSIGNED | docker将任务分配给节点 |
| ACCEPTED | 任务已被工作节点接收,如果辅助几点拒绝任务,则状态改为REJECTED |
| PREPARING | docker正在启动任务 |
| RUNNING | 任务正在执行 |
| COMPLETE | 任务退出 没有错误代码 |
| FAILED | 任务退出并显示错误代码 |
| SHUTDOWN | docker请求关闭任务 |
| REJECTED | 工作节点拒绝了任务 |
| ORPHANED | 节点关闭时间过长 |
| REMOVE | 该任务不是终端,但关联的服务已被删除或者按比例缩小 |
swarm环境搭建
| 主机 | 服务 |
|---|---|
| 192.168.100.211 | docker |
| 192.168.100.212 | docker |
| 192.168.100.213 | docker |
- 注意:docker版本必须一致
- 最好在manager节点搭建一个私有仓库,要不然下载的镜像可能不一致
所有主机
[root@localhost ~]# vim /etc/hosts 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.100.211 node1 192.168.100.212 node2 192.168.100.213 node3 [root@node1 ~]# hostname node1 # 211 [root@node2 ~]# hostname node2 # 212 [root@node3 ~]# hostname node3 # 213 [root@node1 ~]# iptables -F [root@node2 ~]# iptables -F [root@node3 ~]# iptables -F
192.168.100.211对两台主机做免密登录
[root@node1 ~]# ssh-keygen
[root@node1 ~]# ssh-copy-id -i 192.168.100.212
[root@node1 ~]# ssh-copy-id -i 192.168.100.213
192.168.100.211启动swarm
[root@node1 ~]# docker swarm init --advertise-addr 192.168.100.211
Swarm initialized: current node (wtr5cwixf5yj834p81nqbd4ru) is now a manager.
To add a worker to this swarm, run the following command:
# 以worker身份加入集群用下面的命令
docker swarm join --token SWMTKN-1-51c0amrai5ephbnhsnmrah00ni9iko2zvloldxdcln4ahp6swu-68f0mv49it7njsd942rdagtf1 192.168.100.211:2377
# 以 manager身份加入集群用下面的命令
# 不过manager 不能以双数运行 只能以单数运行,最多7个manager 不能少于 (n-1) /2 个
To add a manager to this swarm, run 'docker swarm join-token manager' and follow the instructions.192.168.100.212以worker的身份加入集群
[root@node2 ~]# docker swarm join --token SWMTKN-1-51c0amrai5ephbnhsnmrah00ni9iko2zvloldxdcln4ahp6swu-68f0mv49it7njsd942rdagtf1 192.168.100.211:2377
This node joined a swarm as a worker.
192.168.100.213 以manager身份加入集群
# node1 先查看以manager方式加入的命令
[root@node1 ~]# docker swarm join-token manager
To add a manager to this swarm, run the following command:
# 复制这个就可以以manager加入集群
docker swarm join --token SWMTKN-1-51c0amrai5ephbnhsnmrah00ni9iko2zvloldxdcln4ahp6swu-35ais8910hm4i361kxqi67f4k 192.168.100.211:2377
# 加入集群
[root@node3 ~]# docker swarm join --token SWMTKN-1-51c0amrai5ephbnhsnmrah00ni9iko2zvloldxdcln4ahp6swu-35ais8910hm4i361kxqi67f4k 192.168.100.211:2377
This node joined a swarm as a manager.192.168.100.211 查看
[root@node1 ~]# docker info
Node Address: 192.168.100.211
Manager Addresses:
192.168.100.211:2377
192.168.100.213:2377
# 这个警告是manager不能以双数运行
WARNING: Running Swarm in a two-manager configuration. This configuration provides
no fault tolerance, and poses a high risk to lose control over the cluster.
Refer to https://docs.docker.com/engine/swarm/admin_guide/ to configure the
Swarm for fault-tolerance.
# 查看集群
[root@node1 ~]# docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
wtr5cwixf5yj834p81nqbd4ru * node1 Ready Active Leader 19.03.13
8x4c8yszder0hc4vvlvdqb7o3 node2 Ready Active 19.03.13
kaxa6st33ed2xl03x8q1l71gj node3 Ready Active Reachable 19.03.13
manager降级为worker
docker node demote 节点名称
192.168.100.213 降级为 worker
(192.168.100.211执行) 就是在manager节点执行
[root@node1 ~]# docker node demote node3
Manager node3 demoted in the swarm.
[root@node1 ~]# docker info
Node Address: 192.168.100.211
Manager Addresses:
192.168.100.211:2377
worker 升级为 manager
docker node promote 节点名称
[root@node1 ~]# docker node promote node2
Node node2 promoted to a manager in the swarm.
[root@node1 ~]# docker info
Node Address: 192.168.100.211
Manager Addresses:
192.168.100.211:2377
192.168.100.212:2377将节点踢出集群
docker node rm 节点id \ docker swarm leave -f
将192.168.100.213踢出集群
# 192.168.100.213 退出集群
[root@node3 ~]# docker swarm leave -f
Node left the swarm.
# 192.168.100.211 删除
[root@node1 ~]# docker node rm node3
node3默认的集群管理通讯端口
- 默认的集群管理通讯端口 2377
- TCP/UDP:7946
- 节点间通讯端口:4789
创建service副本
- service不能直接创建容器 但是可以包含多个容器
创建 1个service
docker service create --name service名(也是容器名) 镜像名
[root@node1 ~]# docker service create --name web_server httpd
9kwpu4nki6bzbtkyzffoso5sx
overall progress: 1 out of 1 tasks
1/1: running
verify: Service converged查看service
[root@node1 ~]# docker service ls
ID NAME MODE REPLICAS IMAGE PORTS
9kwpu4nki6bz web_server replicated 1/1 httpd:latest
# Replicas代表这个service有几个副本处于期望状态(副本永远保持这个值不变)
# 查看service里有几个容器
[root@node1 ~]# docker service ps web_server
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
eybppt6sw7ic web_server.1 httpd:latest node1 Running Running 2 minutes ago
# 容器运行在 三个几点的node1中,也就是本地节点
# 查看一下
[root@node1 ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
66e93ff726f7 httpd:latest "httpd-foreground" 3 minutes ago Up 3 minutes 80/tcp web_server.1.eybppt6sw7icb4xb39pp369sy创建多个容器的service副本
docker service create --name service名(也是容器名) --replicas 期望值(容器的数量) 镜像名
[root@node1 ~]# docker service create --name web_server --replicas 2 httpd
kkdd8xaugx1sedqz7zsmy8fit
overall progress: 2 out of 2 tasks
1/2: running
2/2: running
verify: Service converged
# 查看一下
verify: Service converged
[root@node1 ~]# docker service ls
ID NAME MODE REPLICAS IMAGE PORTS
kkdd8xaugx1s web_server replicated 2/2 httpd:latestdocker swarm 页面管理器
dockersamples/visualizer
下载图像化工具镜像
[root@node1 ~]# docker pull dockersamples/visualizer启动容器
[root@node1 ~]# docker run -itd -p 8080:8080 -e HOST=192.168.100.211 -e PORT=8080 --volume /var/run/docker.sock:/var/run/docker.sock --name visualizer --restart always dockersamples/visualizer
b9149ccff2383a1e332dd09e86373707d7c4f6c388faf20082460ddc56d0dfbb
192.168.100.211:8080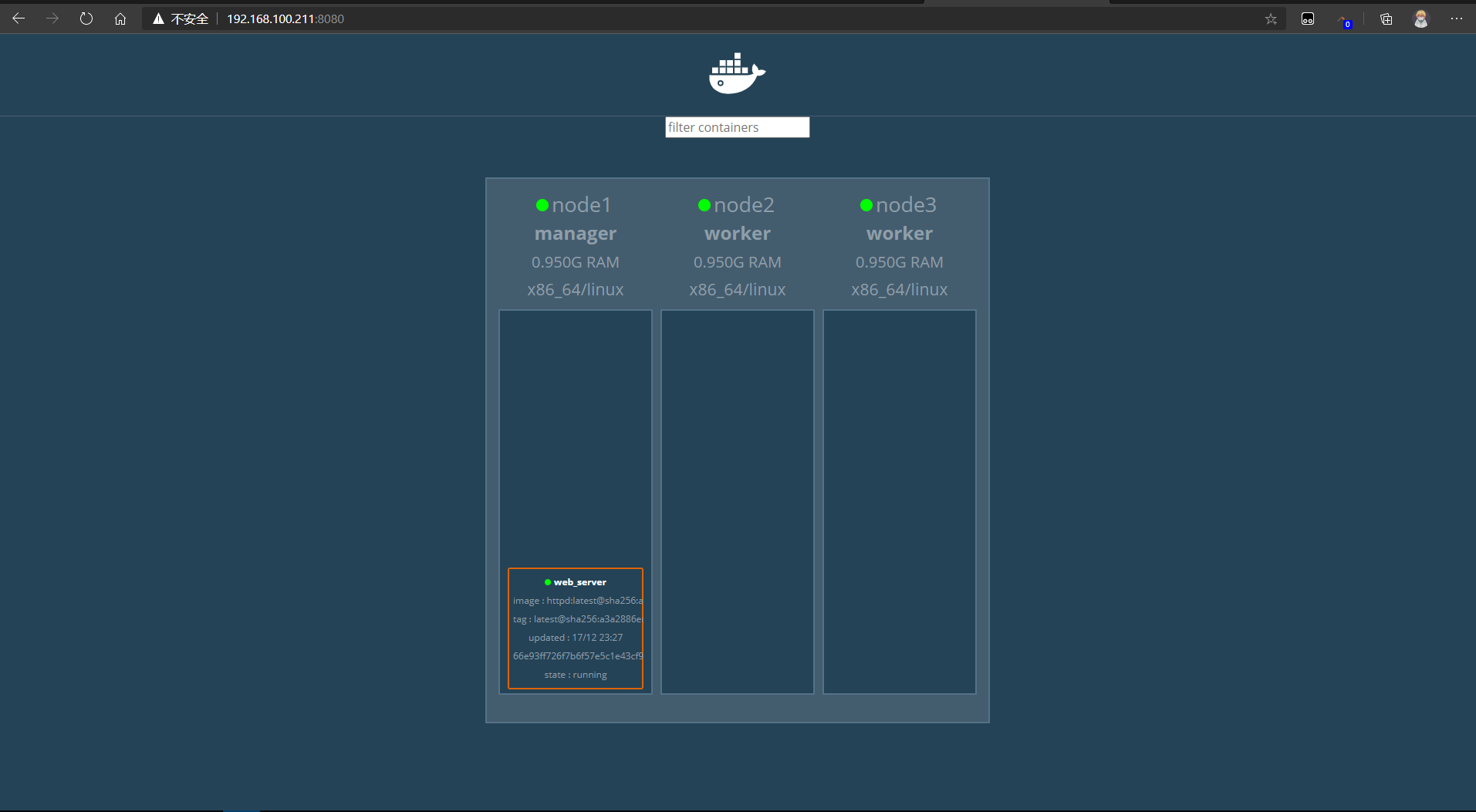
service 弹性伸缩
- 把节点部署伸展为多个
把 web_server伸展为5个
[root@node1 ~]# docker service scale web_server=5
web_server scaled to 5
overall progress: 5 out of 5 tasks
1/5: running
2/5: running
3/5: running
4/5: running
5/5: running
verify: Service converged
# 查看service
[root@node1 ~]# docker service ls
ID NAME MODE REPLICAS IMAGE PORTS
9kwpu4nki6bz web_server replicated 5/5 httpd:latest
# 该service有5个副本了
# 查看每个每个节点运行了哪些容器
[root@node1 ~]# docker service ps web_server
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
eybppt6sw7ic web_server.1 httpd:latest node1 Running Running 17 minutes ago
78p5ppn6xxfu web_server.2 httpd:latest node3 Running Running 2 minutes ago
mbfwslol227h web_server.3 httpd:latest node3 Running Running 2 minutes ago
wy3mxtsmcrto web_server.4 httpd:latest node1 Running Running 2 minutes ago
y28opcrl5dl8 web_server.5 httpd:latest node2 Running Running 2 minutes ago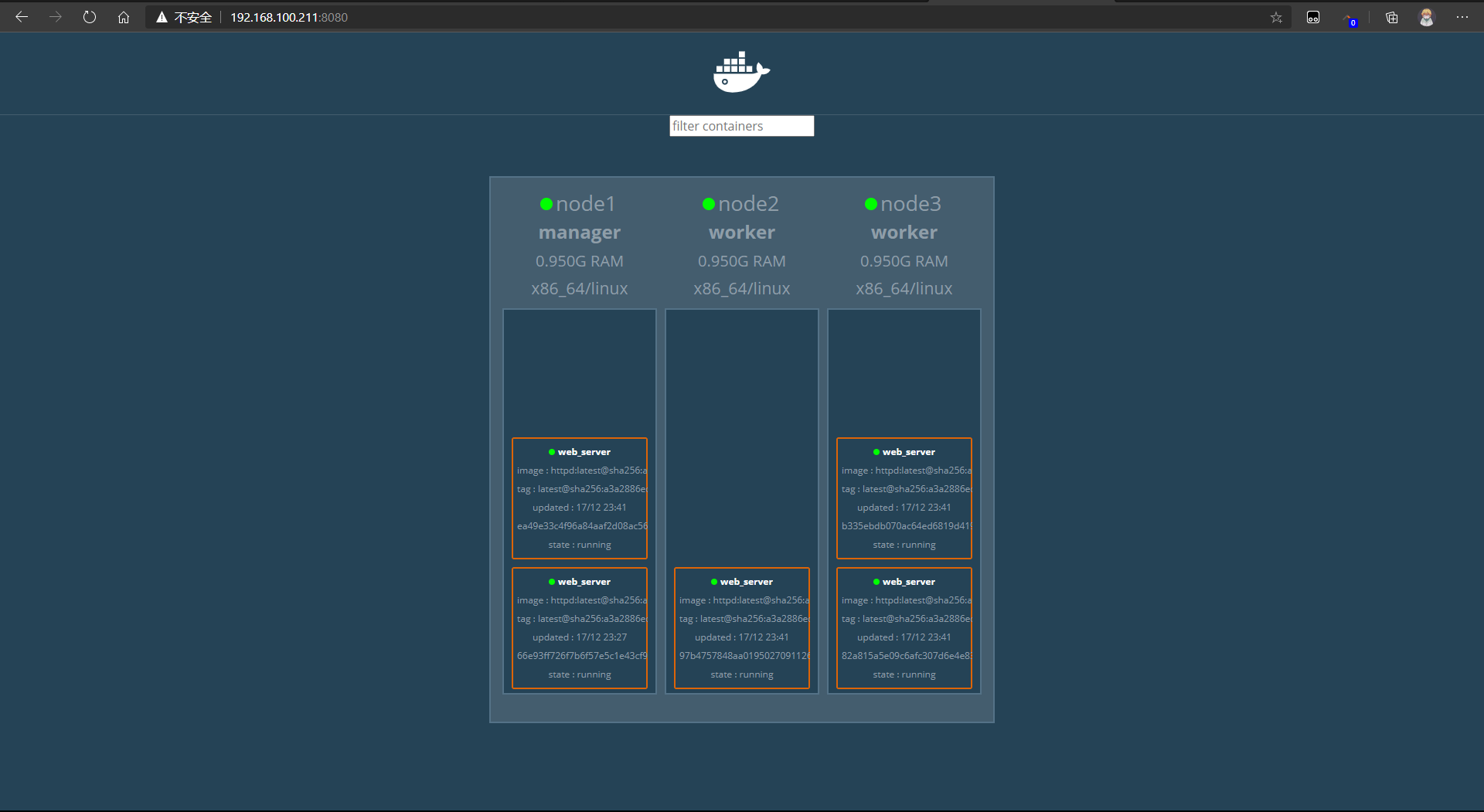
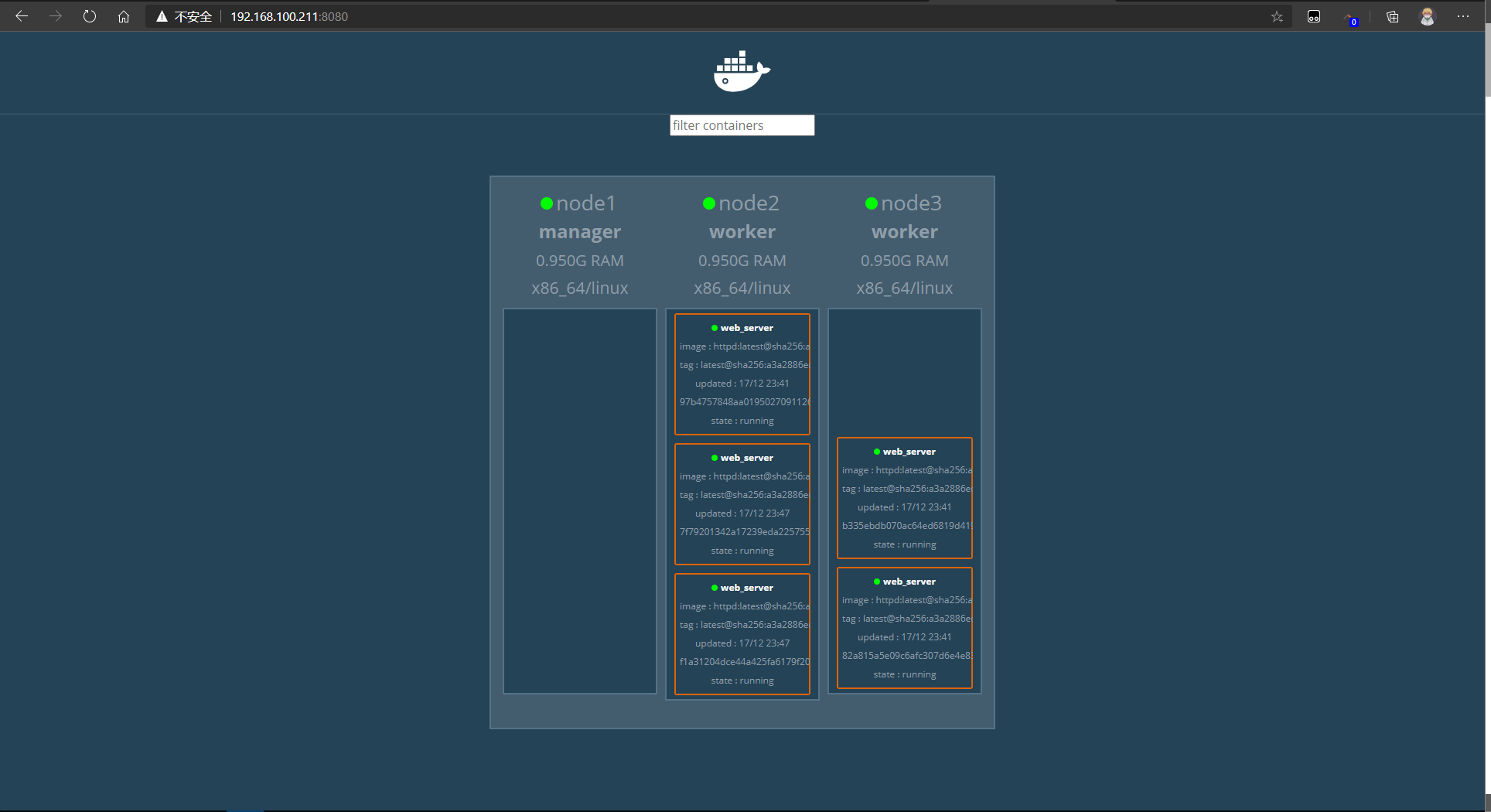
manager 取消运算
- 一般情况下,manager上不参与运算,只需要分配和调度任务—也就将模式active->drain
docker node update --availability drain 节点名称
# manager取消运算
drain 下水道模式 就是不参与运算了只负责分配任务
[root@node1 ~]# docker node update --availability drain node1
node1
# 查看 node1 已经变成 drain了
[root@node1 ~]# docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
wtr5cwixf5yj834p81nqbd4ru * node1 Ready Drain Leader 19.03.13
8x4c8yszder0hc4vvlvdqb7o3 node2 Ready Active 19.03.13
oyu1h6nqhwc05h41qjopjhtz4 node3 Ready Active 19.03.13
- node1没有运行的容器了
manager 参与运算
docker node update --availability active 节点名称
[root@node1 ~]# docker node update --availability active node1
node1
# 查看
[root@node1 ~]# docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
wtr5cwixf5yj834p81nqbd4ru * node1 Ready Active Leader 19.03.13
8x4c8yszder0hc4vvlvdqb7o3 node2 Ready Active 19.03.13
oyu1h6nqhwc05h41qjopjhtz4 node3 Ready Active 19.03.13- 重新让manager参与运算容器也不会重新迁移到原来的地方
service缩减副本
- 和增加副本一样,只需要把副本的数量改少就可以了
# 现在有5个 [root@node1 ~]# docker service ls ID NAME MODE REPLICAS IMAGE PORTS 9kwpu4nki6bz web_server replicated 5/5 httpd:latest # 缩减为3个副本 [root@node1 ~]# docker service scale web_server=3 web_server scaled to 3 overall progress: 3 out of 3 tasks 1/3: 2/3: running 3/3: running verify: Service converged # 查看一下 [root@node1 ~]# docker service ls ID NAME MODE REPLICAS IMAGE PORTS 9kwpu4nki6bz web_server replicated 3/3 httpd:latest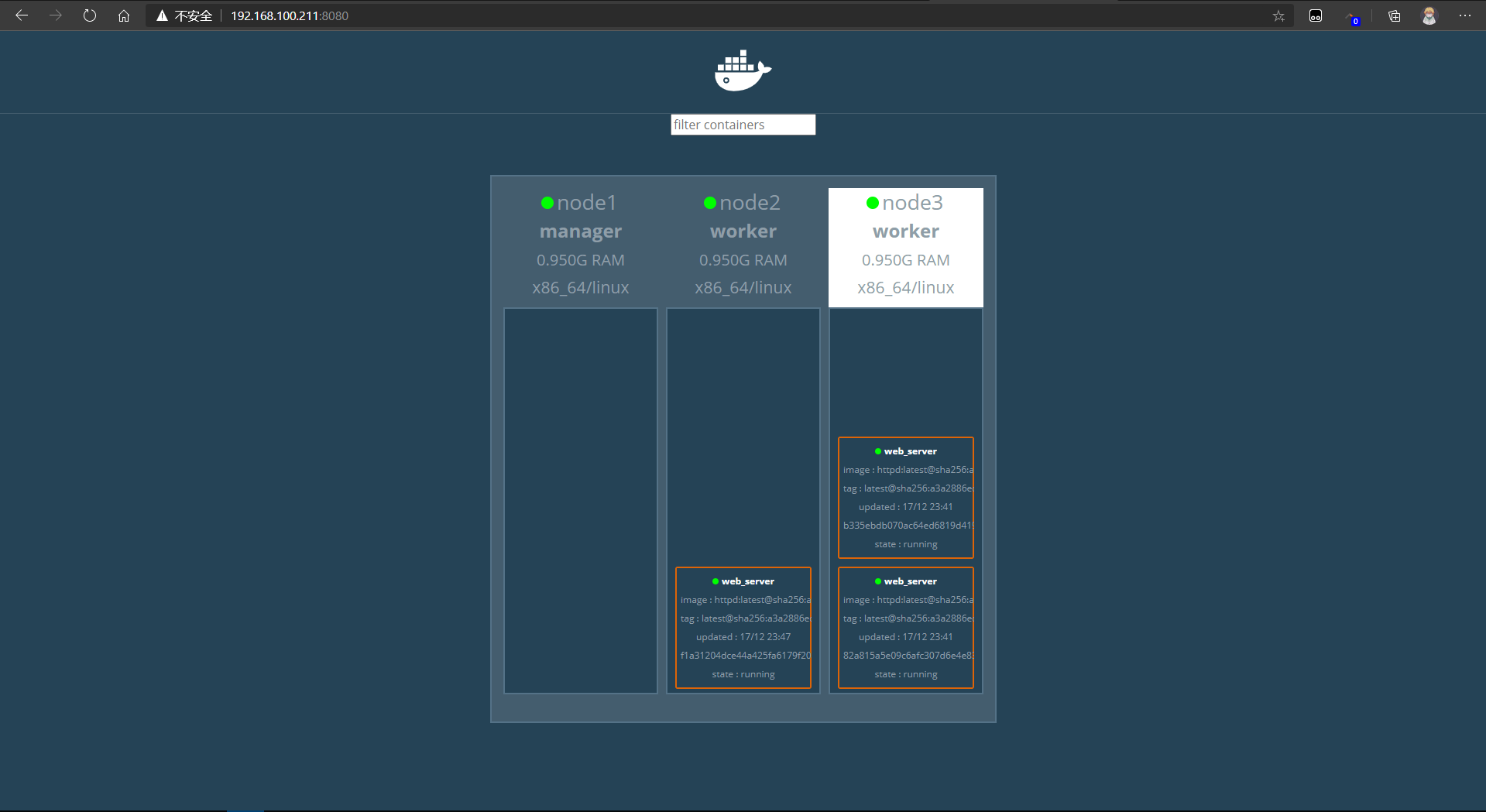
删除 service
docker service rm service名称
# 删除 web-server节点
[root@node1 ~]# docker service rm web_server
web_server
[root@node1 ~]# docker service ls
ID NAME MODE REPLICAS IMAGE PORTS
swarm集群端口映射
创建一个service副本
[root@node1 ~]# docker service create --name web_server --replicas 2 httpd
kkdd8xaugx1sedqz7zsmy8fit
overall progress: 2 out of 2 tasks
1/2: running
2/2: running
verify: Service converged
[root@node1 ~]# docker service ls
ID NAME MODE REPLICAS IMAGE PORTS
kkdd8xaugx1s web_server replicated 2/2 httpd:latest增加端口映射
docker service update --publish-add 主机端口:容器端口 service副本名称
[root@node1 ~]# docker service update --publish-add 80:80 web_server
web_server
overall progress: 2 out of 2 tasks
1/2: running
2/2: running
verify: Service converged
# 访问
[root@node1 ~]# curl 192.168.100.211
<html><body><h1>It works!</h1></body></html>
Routing mesh
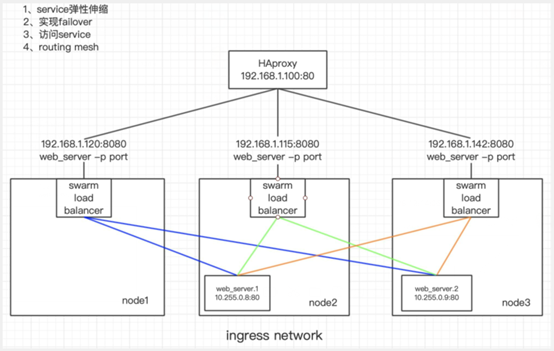
- 计算机内部有个 swarm load balance 服务
- 当访问到 80端口后 docker都会将所有请求发送到活动的容器上,在集群节点本身上 80端口没有被绑定,但路由网格防止发生端口冲突,会给每个节点分配一个ip 进行内部访问,这个网络叫ingress网络
# 查看网卡 [root@node1 ~]# docker network ls NETWORK ID NAME DRIVER SCOPE 48ceedaeac62 bridge bridge local ca5db32546cb docker_gwbridge bridge local dc088ea51e19 host host local lu1ybn8aesmn ingress overlay swarm cec68349a7d5 none null local # 发现多出来一个 ingress 网卡 # 查看详细信息 [root@node1 ~]# docker network inspect ingress "Config": [ { "Subnet": "10.0.0.0/24", "Gateway": "10.0.0.1" } ] # 为10网段 - routing mesh可以将外部的请求路由到不同的容器内,从而实现外部网络对service的访问。
- service和service之间通讯是因为服务发现
service 之间的服务发现
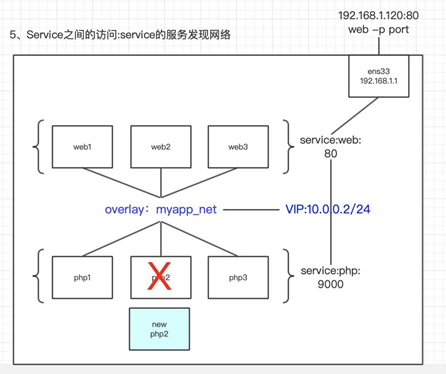
- 相同的容器会放在同一个service 容器易变化(迁移、增加、伸缩)需要知道想连的数据变化
- 比如
有3个service nginx mysql php
如果数据写入量巨大,就增加mysql的容器数量,那么php就要通过服务发现去发现新增加的这些mysql
如果 php中有一个容器坏掉了那么nginx在分配请求时,就需要服务发现,来避免往哪个坏掉的php来发送请求
- ingress 网卡只能做到一个service当中的负载均衡,是不能够服务发现的,所以需要创建overlay网卡来进行服务发现
创建overlay网卡
# 创建网卡
[root@node1 ~]# docker network create --driver overlay myapp_net
aubwvrdcez7l37vjxund70nul
# 查看
[root@node1 ~]# docker network ls
NETWORK ID NAME DRIVER SCOPE
48ceedaeac62 bridge bridge local
ca5db32546cb docker_gwbridge bridge local
dc088ea51e19 host host local
lu1ybn8aesmn ingress overlay swarm
aubwvrdcez7l myapp_net overlay swarm
cec68349a7d5 none null local
# worker节点没有同步
[root@node2 ~]# docker network ls
NETWORK ID NAME DRIVER SCOPE
bbaffe7597dc bridge bridge local
a357bf02cc8b docker_gwbridge bridge local
433526ca900b host host local
lu1ybn8aesmn ingress overlay swarm
595c66e2ae10 none null local
# swarm局限在某一范围内,只在swarm有效创建 service副本
[root@node1 ~]# docker service create --name util --network myapp_net busybox sleep 10000000
8kt8b8cbwp562ua0c4y9gjluf
overall progress: 1 out of 1 tasks
1/1: running
verify: Service converged
# 创建3个httpd
[root@node1 ~]# docker service create --name lmk_web --network myapp_net --replicas 3 httpd
mvd8nmb6vuob31zuo2z5kpbtq
overall progress: 3 out of 3 tasks
1/3: running
2/3: running
3/3: running
verify: Service converged
# 都指定的是一个网卡进入util容器访问三个httpd服务
[root@node1 ~]# docker service ps util
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
lbp4islu0lz0 util.1 busybox:latest node2 Running Running about a minute ago
# util ping lmk_web
[root@node2 ~]# docker exec -it util.1.lbp4islu0lz02qjdh7m6k6wt9 sh
/ # ping lmk_web
PING lmk_web (10.0.1.5): 56 data bytes
64 bytes from 10.0.1.5: seq=0 ttl=64 time=0.111 ms
64 bytes from 10.0.1.5: seq=1 ttl=64 time=0.069 ms
# 发现ping的是 10.0.1.5
# 那么查看三个 httpd的ip
[root@node2 ~]# docker inspect lmk_web.2.x7753z1m21loqp1iy7314w6b2
"IPAddress": "10.0.1.7",
[root@node3 ~]# docker inspect lmk_web.1.id9r3j9ur9ey450gu9exz3azw
"IPAddress": "10.0.1.6",
[root@node3 ~]# docker inspect lmk_web.3.tcvk0uoqpkbase90h8xazl5n6
"IPAddress": "10.0.1.8",
# 发现都不是 10.0.1.5- 那么10.0.1.5是什么呢,
# 查看lmk_web这个service [root@node1 ~]# docker inspect lmk_web "Endpoint": { "Spec": { "Mode": "vip" }, "VirtualIPs": [ { "NetworkID": "aubwvrdcez7l37vjxund70nul", "Addr": "10.0.1.5/24" } ] } # 会发现10.0.1.5这个ip在这里 # 服务发现采用的方式为VIP 将10.0.1.5 分配为 vip 其他服务访问到这个服务只需要访问这个ip就可以访问到服务了
swarm回滚更新
- 生产环境中,某个数据需要向里面部署新的代码,就需要把新的代码打包到新的镜像中,新的镜像就会替代原来容器中的镜像,即为滚动更新,如果代码有bug,就需要回滚。
查看当前 service的版本
[root@node1 ~]# docker service ps lmk_web ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS id9r3j9ur9ey lmk_web.1 httpd:latest node3 Running Running 11 minutes ago x7753z1m21lo lmk_web.2 httpd:latest node2 Running Running 12 minutes ago tcvk0uoqpkba lmk_web.3 httpd:latest node3 Running Running 11 minutes ago # 为最新版更新到 2.4.32版本 (降级也叫更新)
[root@node1 ~]# docker service update --image httpd:2.4.32 lmk_web lmk_web overall progress: 3 out of 3 tasks 1/3: running 2/3: running 3/3: running verify: Service converged [root@node1 ~]# docker service ps lmk_web ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS yeqaksw5qjel lmk_web.1 httpd:2.4.32 node3 Running Running 42 seconds ago id9r3j9ur9ey \_ lmk_web.1 httpd:latest node3 Shutdown Shutdown 59 seconds ago smhb2pf9eaia lmk_web.2 httpd:2.4.32 node2 Running Running 24 seconds ago x7753z1m21lo \_ lmk_web.2 httpd:latest node2 Shutdown Shutdown 32 seconds ago r7h5rm6h13bz lmk_web.3 httpd:2.4.32 node3 Running Running 37 seconds ago tcvk0uoqpkba \_ lmk_web.3 httpd:latest node3 Shutdown Shutdown 37 seconds ago # 会发现是先停掉 一个在启动一个 这是避免不能对外进行服务调整副本总量为6个 每次更新2个 1m30s更新一次
[root@node1 ~]# docker service update --replicas 6 --update-parallelism 2 --update-delay 1m30s lmk_web lmk_web overall progress: 6 out of 6 tasks 1/6: running 2/6: running 3/6: running 4/6: running 5/6: running 6/6: running verify: Service converged # 查看 [root@node1 ~]# docker service ps lmk_web ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS yeqaksw5qjel lmk_web.1 httpd:2.4.32 node3 Running Running 3 minutes ago id9r3j9ur9ey \_ lmk_web.1 httpd:latest node3 Shutdown Shutdown 3 minutes ago smhb2pf9eaia lmk_web.2 httpd:2.4.32 node2 Running Running 3 minutes ago x7753z1m21lo \_ lmk_web.2 httpd:latest node2 Shutdown Shutdown 3 minutes ago r7h5rm6h13bz lmk_web.3 httpd:2.4.32 node3 Running Running 3 minutes ago tcvk0uoqpkba \_ lmk_web.3 httpd:latest node3 Shutdown Shutdown 3 minutes ago 5dz0cc4j4e8r lmk_web.4 httpd:2.4.32 node2 Running Running about a minute ago yxzjha6hbao6 lmk_web.5 httpd:2.4.32 node2 Running Running about a minute ago uv9db0moba6a lmk_web.6 httpd:2.4.32 node3 Running Running about a minute ago - 回滚——docker swarm 只能回滚到上一次执行docker service update之前的状态,并不能无限回滚
- 只能回滚最后两次的版本
swarm 数据迁移
- tasks
swarm 数据映射
swarm 健康检查
本博客所有文章是以学习为目的,如果有不对的地方可以一起交流沟通共同学习 邮箱:1248287831@qq.com!